map阶段和 reduce阶段
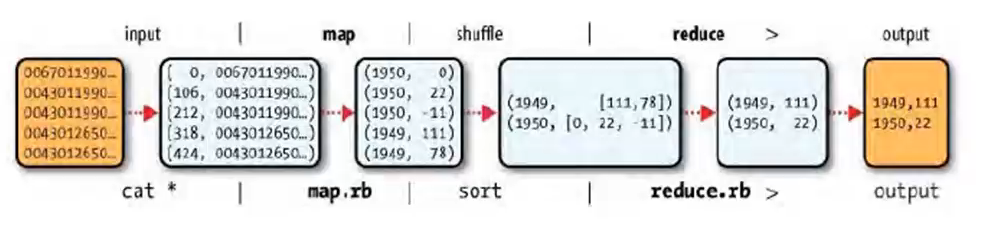
Mapreduce任务过程被分为两个处理阶段:map阶段和 reduce阶段。每个阶段都以键/值对作为输入和输出,井由程序员选择它们的类型。程序员还需具体定义两个函数:map函数和 reduce函数。
map阶段的输人是原始NCDC数据。我们选择文本格式作为输入格式,以便将数据集的每一行作为一个文本值进行输入。键为该行起始位置相对于文件起始位置的偏移量,但我们不需要这个信息,故将其忽略。
 调度机制
调度机制
- 缺省为先入先出作业队列调度
- 支持公平调度器
- 支持容量调度器
任务执行优化
推测式执行:即如果 jobtracker发现有拖后腿的任务,会再启动一个相同的备份任务然后哪个先执行完就会kill去另外一个,因此在监控网页上经常能看到正常执行完的作业有被kill掉的任务
推测式执行缺省打开,但如果是代码问题,并不能解决问题,而且会使集群更慢,通过在mapred-site.xm配置文件中设置 mapred. map tasks.speculative.execution和mapred. reduce.tasks. speculative.execution可为map任务或 reduce任务开启或关闭推测式执行
重用JVM,可以省去启动新的JVM消耗的时间,在 mapped- site. xm配置文件中设置mapred.job.reuse jvm.nun.tasks设置单个JVM上运行的最大任务数(1,>1或-1表示没有限制)
忽略模式,任务在读取数据失败2次后,会把数据位置告诉 jobtracker,后者重新启动该任务并且在遇到所记录的坏数据时直接跳过(缺省关闭,用 Skipbadrecorc方法打开)
错误处理机制:硬件故障
- 硬件故障是指jobtracker故障或tasktracker故障
- jobtracker是单点,若发生故障目前hadoop还无法处理,唯有选择最牢靠的硬件作为jobtracker
- jobtracker通过心跳(周期1分钟)信号了解tasktracker是否发生故障或负载过于严重
- jobtracker将从任务节点列表中移除发生故障的tasktracker
- 如果故障节点在执行map任务并且尚未完成,jobtracker会要求其他节点重新执行此map任务
- 如果故障节点在执行reduce任务并且尚未完成,jobtracker会要求其他节点重新执行尚未完成的reduce任务
错误处理机制:任务失败
- 由于代码缺陷或进程崩溃引起任务失败
- Jvm自动退出,向 tasktracker父进程发送方错误信息,错误信息也会写入到日志
- Tasktracker监听程序会发现进程退出,或进程很久没有更新信息送回,将任务标记为失败
- 标记失败任务后,任务计数器减去1以便接受新任务,并通过心跳信号告诉 jobtracker任务失败的信息
- jobptrack获悉任务失败后,将把该任务重新放入调度队列,重新分配出去再执行
- 如果一个任务失败超过4次(可以设置),将不会再被执行,同时作业也宣布失败