KMP算法
KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。
给定两个字符串T和W,长度分别为m和n,判断W是否在T中出现,如果出现则返回出现的位置。常规方法是遍历T的每一个位置,然后从该位置开始和W进行匹配,但是这种方法的复杂度是O(mn)。kmp算法通过一个O(n)的预处理,使匹配的复杂度降为O(m+n)。
我们要在 字符串T=“ABCDABCDABDE”中查找 字符串W="ABCDABD"出现的位置。
 |
|---|
很明显可以看出前6位都是匹配的,然而第7位不匹配,一般的做法就是从T[i](i从1到9)开始和W开始循环比较。直到i=4,也就是图2,比较成功返回下标4。
 |
|---|
这样比较无异效率很低,然而我们发现在字符串"ABCDAB"之中有两个"AB",第一次比较失败之后,又循环比较了四次,把W字符串从第一个"AB"的位置移动到了第二个"AB"处(显然这四次比较毫无意义)。于是Knuth、Morris、Pratt这三个人就想了个办法去掉了这些无意义的比较。
然而是怎么实现的呢?就要从W字符串的部分匹配值(相等的前缀和后缀)说起。
部分匹配值
"前缀"指除了最后一个字符以外,一个字符串的全部头部组合;
"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以W字符串"ABCDABD"为例:
"A"的前缀和后缀都为空集,共有元素的长度为0;
"AB"的前缀为[A],后缀为[B],共有元素的长度为0;
"ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
"ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
"ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
"ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
"ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
从上面我们就得出了字符串W的部分匹配表:
 |
|---|
我们把部分匹配表存放在一个next[]数组中,那部分匹配值究竟怎么用呢? 我们可以根据部分匹配值计算出向后移动的位数,避免了一位位的比较:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
以图1中为例:
前6位已经匹配(已匹配的字符数 =6);next[5] = 2 (对应的部分匹配值 = 2); 我们可以得出移动位数为 6-2=4位。
可以看出next数组的作用,就是在我们匹配失败的时候,确定我们子串需要往后移动的距离,而避免我们的主串指针进行回退。这样可以保证主串在只遍历一遍的情况下找到子串。因此KMP算法的重点就是如何快速的求出这个next数组。
2 求next数组
next数组是只与子串有关与主串无关的,它记录的是子串到每个字符处那个公共前缀(或后缀)的最大长度。
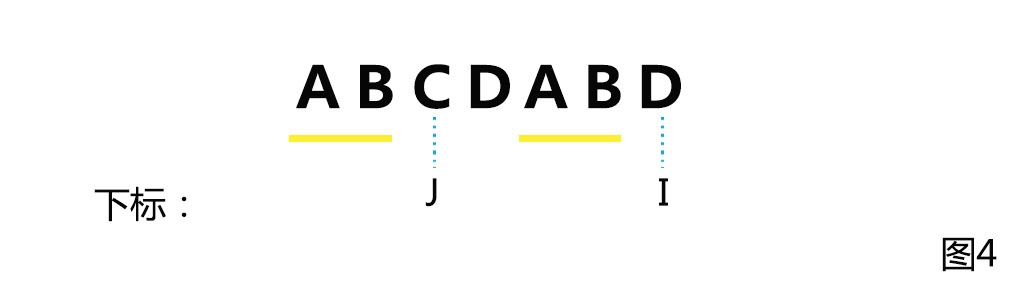 |
|---|
假设我们已经求出的next[i-1] = j,即W从0到i-1处这段字符串中,最大的相等的前缀和后缀长度为j。 那如何求得next[i]呢?
这是后就要分为两种情况了:
如果W[i]==W[j]
显然前缀往后再加上一个字符之后依然会和后缀往后加上一个字符相等,此时next[i] = next[i-1] + 1,即next[i] = j+1如果W[i]!=W[j]
那么 W[0-i]这段字符串 中,最大的相等的前缀和后缀的长度必然小于等于j。 (以前是j,现在加了一个不同字符,所以不可能大于j)。
从上面的W字符串的前缀分析可以看出,短字符串的前缀必是长字符串前缀的子集。
既然长的匹配值不行了,我们只能回溯到短的匹配。把j下标循环向前(下标0方向)移动,直到W[j]W[i]或者j0为止(回到第一种情况)。
那么j怎么移动呢?当前W[i]!=W[j],那么就求0到j-1的最长匹配值(next[j - 1]),再比较这个最长匹配串的末尾字符的下一位是否等于w[i],不相等再循环。
Java代码
private static int[] getNextArray(String s){
char[] ch = s.toCharArray();
int i,j;
int[] next = new int[ch.length];
for(i = 1,j = 0; i < ch.length; i++){
while(j > 0 && ch[i] != ch[j]){
j = next[j - 1]; //j <next[j - 1],所以向前移动
}
if(ch[i] == ch[j]){
j++;
}
next[i] = j;
}
return next;
}
W字符串"ABCDABD"为例,运行结果如下:
0
0
0
0
1
2
0
KMP
其实进行next数组求解的过程,类似于主串和子串进行匹配的过程,只不过是在next数组求解过程中,是子串和子串自己进行比较而已。
因此整个KMP算法的代码过程如下:
/**
* @param str1 被匹配的字符串
* @param str2 子串
* @return 布尔值
*/
public static boolean kmp(String str1,String str2){
char[] strA = str1.toCharArray();
char[] strB = str2.toCharArray();
int[] next = getNextArray(str2);
int i,j; //这里i是从0开始的
for(i = 0,j = 0; i < strA.length; i++){
while(j > 0 && strA[i] != strB[j])
j = next[j-1];
if(strA[i] == strB[j]){
j++;
}
//匹配成功
if(j == strB.length){
return true;
}
}
return false;
}
private static int[] getNextArray(String s){
char[] ch = s.toCharArray();
int i,j;
//数组初始全部为0,所以next[0]=0
int[] next = new int[ch.length];
for(i = 1,j = 0; i < ch.length; i++){
while(j > 0 && ch[i] != ch[j]){
//j <next[j - 1],所以向前移动
j = next[j - 1];
}
if(ch[i] == ch[j]){
j++;
}
next[i] = j;
}
return next;
}
public static void main(String[] args) {
String T ="ABCDABCDABDE";
String W = "ABCDABD";
System.out.println(kmp(T,W));
}
运行结果:
true